Main difference between UTF-8, UTF-16 and UTF-32 character encoding is how many bytes it require to represent a character in memory. UTF-8 uses minimum one byte, while UTF-16 uses minimum 2 bytes. BTW, if character's code point is greater than 127, maximum value of byte then UTF-8 may take 2, 3 o 4 bytes but UTF-16 will only take either two or four bytes. On the other hand, UTF-32 is fixed width encoding scheme and always uses 4 bytes to encode a Unicode code point. Now, let's start with what is character encoding and why it's important? Well, character encoding is an important concept in process of converting byte streams into characters, which can be displayed. There are two things, which are important to convert bytes to characters, a character set and an encoding. Since there are so many characters and symbols in the world, a character set is required to support all those characters. A character set is nothing but list of characters, where each symbol or character is mapped to a numeric value, also known as code points.
On the other hand UTF-16, UTF-32 and UTF-8 are encoding schemes, which describe how these values (code points) are mapped to bytes (using different bit values as a basis; e.g. 16-bit for UTF-16, 32 bits for UTF-32 and 8-bit for UTF-8). UTF stands for Unicode Transformation, which defines an algorithm to map every Unicode code point to a unique byte sequence.
For example, for character A, which is Latin Capital A, Unicode code point is U+0041, UTF-8 encoded bytes are 41, UTF-16 encoding is 0041 and Java char literal is '\u0041'. In short, you must need a character encoding scheme to interpret stream of bytes, in the absence of character encoding, you cannot show them correctly. Java programming language has extensive support for different charset and character encoding, by default it use UTF-8.
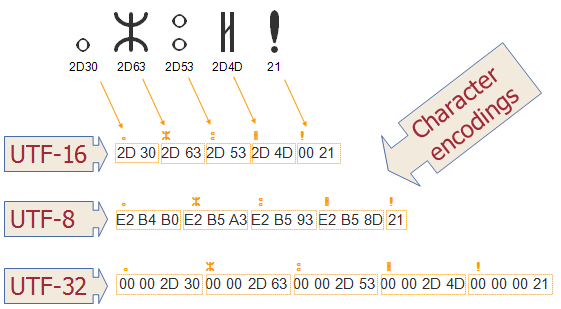
Here is an example, which shows how different characters are mapped to bytes under different character encoding scheme e.g. UTF-16, UTF-8 and UTF-32. You can see how different scheme takes different number of bytes to represent same character.
2) You might think that because UTF-8 take less bytes for many characters it would take less memory that UTF-16, well that really depends on what language the string is in. For non-European languages, UTF-8 requires more memory than UTF-16.
3) ASCII is strictly faster than multi-byte encoding scheme because less data to process = faster.
That's all about Unicode, UTF-8, UTF-32 and UTF-16 character encoding. As we have learned, Unicode is a character set of various symbol, while UTF-8, UTF-16 and UTF-32 are different ways to represent them in byte format. Both UTF-8 and UTF-16 are variable length encoding, where number of bytes used depends upon Unicode code points. On the other hand UTF-32 is fixed width encoding, where each code point takes 4 bytes. Unicode contains code points for almost all represent-able graphic symbols in the world and it supports all major languages e.g. English, Japanese, Mandarin or Devanagari.
Always remember, UTF-32 is fixed width encoding, always takes 32 bits, but UTF-8 and UTF-16 are variable length encoding where UTF-8 can take 1 to 4 bytes while UTF-16 will take either 2 or 4 bytes.
On the other hand UTF-16, UTF-32 and UTF-8 are encoding schemes, which describe how these values (code points) are mapped to bytes (using different bit values as a basis; e.g. 16-bit for UTF-16, 32 bits for UTF-32 and 8-bit for UTF-8). UTF stands for Unicode Transformation, which defines an algorithm to map every Unicode code point to a unique byte sequence.
For example, for character A, which is Latin Capital A, Unicode code point is U+0041, UTF-8 encoded bytes are 41, UTF-16 encoding is 0041 and Java char literal is '\u0041'. In short, you must need a character encoding scheme to interpret stream of bytes, in the absence of character encoding, you cannot show them correctly. Java programming language has extensive support for different charset and character encoding, by default it use UTF-8.
Difference between UTF-32, UTF-16 and UTF-8 encoding
As I said earlier, UTF-8, UTF-16 and UTF-32 are just couple of ways to store Unicode codes points i.e. those U+ magic numbers using 8, 16 and 32 bits in computer's memory. Once Unicode character is converted into bytes, it can be easily persisted in disk, transferred over network and recreated at other end. Fundamental difference between UTF-32 and UTF-8, UTF-16 is that former is fixed width encoding scheme, while later duo is variable length encoding. BTW, despite, both UTF-8 and UTF-16 uses Unicode characters and variable width encoding, there are some difference between them as well.1) UTF-8 uses one byte at the minimum in encoding the characters while UTF-16 uses minimum two bytes.
In UTF-8, every code point from 0-127 is stored in a single bytes. Only code points 128 and above are stored using 2,3 or in fact, up to 4 bytes. In short, UTF-8 is variable length encoding and takes 1 to 4 bytes, depending upon code point. UTF-16 is also variable length character encoding but either takes 2 or 4 bytes. On the other hand UTF-32 is fixed 4 bytes.2) UTF-8 is compatible with ASCII while UTF-16 is incompatible with ASCII
UTF-8 has an advantage where ASCII are most used characters, in that case most characters only need one byte. UTF-8 file containing only ASCII characters has the same encoding as an ASCII file, which means English text looks exactly the same in UTF-8 as it did in ASCII. Given dominance of ASCII in past this was the main reason of initial acceptance of Unicode and UTF-8.Here is an example, which shows how different characters are mapped to bytes under different character encoding scheme e.g. UTF-16, UTF-8 and UTF-32. You can see how different scheme takes different number of bytes to represent same character.
Summary
1) UTF16 is not fixed width. It uses 2 or 4 bytes. Only UTF32 is fixed-width and unfortunately no one uses it. Also, worth knowing is that Java Strings are represented using UTF-16 bit characters, earlier they use USC2, which is fixed width.
2) You might think that because UTF-8 take less bytes for many characters it would take less memory that UTF-16, well that really depends on what language the string is in. For non-European languages, UTF-8 requires more memory than UTF-16.
3) ASCII is strictly faster than multi-byte encoding scheme because less data to process = faster.
Always remember, UTF-32 is fixed width encoding, always takes 32 bits, but UTF-8 and UTF-16 are variable length encoding where UTF-8 can take 1 to 4 bytes while UTF-16 will take either 2 or 4 bytes.
No comments:
Post a Comment